로지스틱 회귀
- 회귀 알고리즘을 분류 문제에 사용할 때 로지스틱 회귀 사용
1. 확률 추정
- 결과 값에 시그모이드 함수를 씌워 0과 1사이의 (확률) 값으로 변환해줌
- 로지스틱 회귀 모델의 확률 추정(벡터 표현식)
$ \hat{p} = h_{\theta} (x) = \sigma ( \theta^{T} x ) $
- 로지스틱 함수
$ \sigma (t) = $ $ 1 \over 1+exp(-t) $

2. 클래스 예측

3. 훈련과 비용 함수
- 훈련할 때, 양성 샘플 (y=1)은 높은 확률을 정하고, 음성 샘플(y=0)은 낮은 확률을 추정하는 모델의 파라미터 $ \theta $를 찾음
- 식 4-16에 t가 0에 가까워질수록 -log(t)가 매우 커짐 (틀릴수록, 비용이 커짐)
- 전체 비용 함수는 전체 데이터 셋의 식 4-16을 평균한 것 (식 4-17)
- 식 4-17의 비용함수는 정규방정식처럼 알려진 최솟값을 계산하는 식이 없음
(그러나 볼록함수 이므로 경사하강법이 전역 최솟값을 찾는 것을 보장)


python 코드
- 사이킷 런 : LogisticRegression()
소프트맥스 회귀(=다항 로지스틱 회귀)
- 로지스틱이 다중 클래스를 지원화도록 일반화 된 모델
1. 확률 추정
- 샘플 x가 주어지면 각 클래스 k에 대한 점수 $s_{k} x$를 계산 (식 4-19)
- 각 클래스의 점수 $s_{k} x$가 계산되면 소프트맥스 함수(식4-20)에 통과 (결과 = 클래스 k에 속할 확률)
- 예측시 추정 확률이 가장 높은 클래스를 선택 (식4-21)

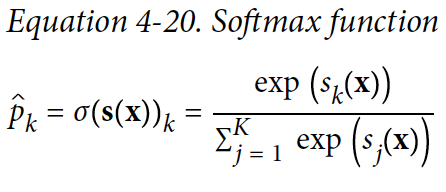

2. 훈련 방법
- 크로스 엔트로피 비용 함수 최소화하여 사용
(타깃 클래스는 높은 확률, 다른 클래스에는 낮은 확률을 부여하도록 추정)
- 클래스가 2개일 땐 로지스틱 비용함수와 동일

python 코드
- 사이킷 런 : LogisticRegression(multi_class="multinomial")
'* [R_Python] 데이터분석 정리 > [Python] 머신러닝' 카테고리의 다른 글
| 경사 하강법의 조기 종료 (0) | 2021.07.18 |
|---|---|
| 규제가 있는 선형 모델 (릿지,라쏘,엘라스틱넷) (0) | 2021.07.18 |
| 결정 트리 - Decision Tree #이론 + 파이썬 코드 #쉬운 정리 (0) | 2020.11.24 |


